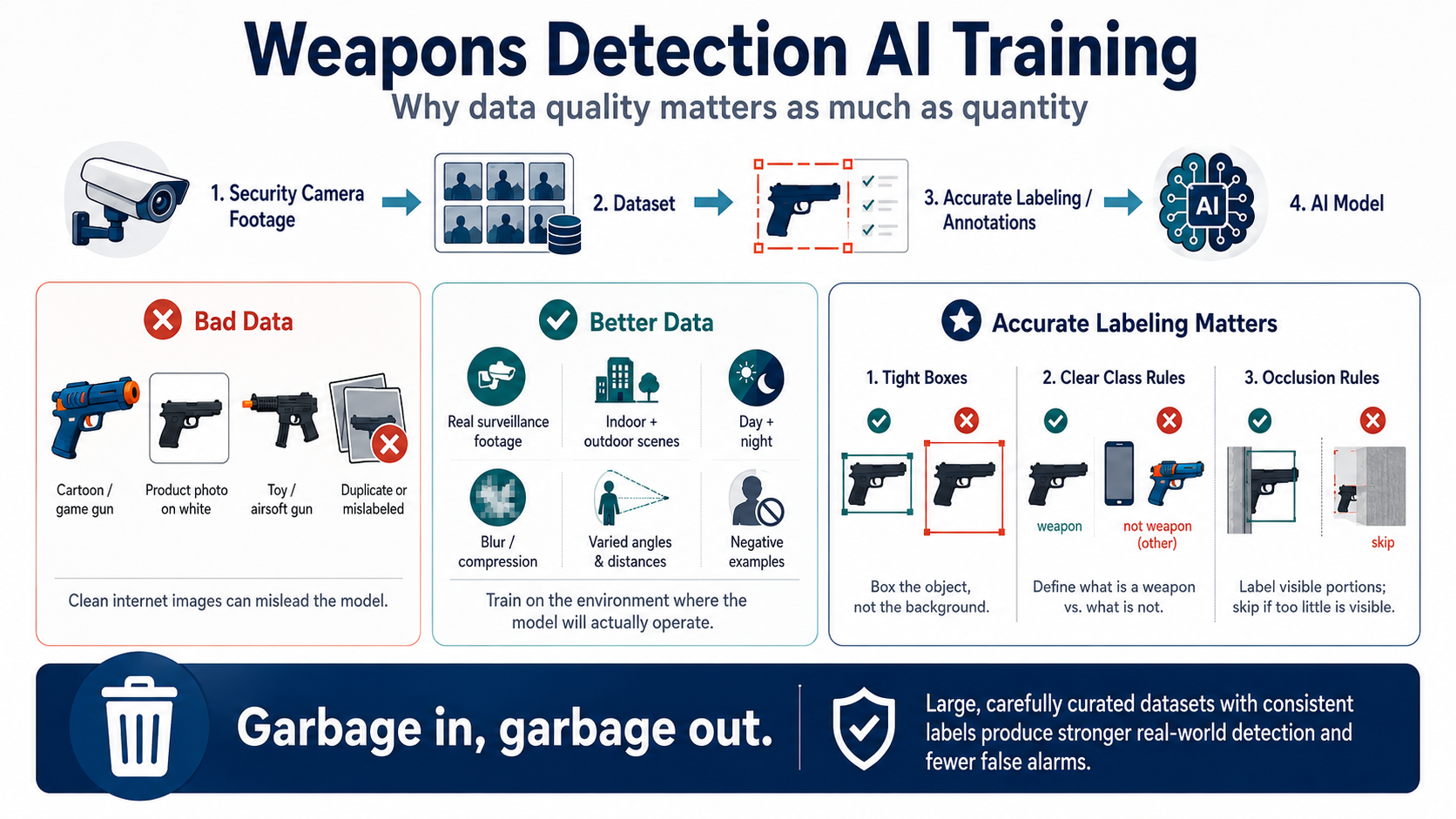
Training or fine-tuning a vision detection model is not just about collecting thousands of images and feeding them into an AI system. For security analytics, weapons detection, vehicle classification, people detection, or other real-world computer vision tasks, the quality of the image data is just as important as the quantity. A model trained on poor, misleading, or unrealistic images may look good in a lab test but fail badly when deployed in the real world.
How Vision Models Are Trained or Fine-Tuned
A vision model learns by analyzing many labeled images and adjusting its internal patterns until it can recognize objects, features, or categories on its own. In training or fine-tuning, images are typically labeled with object classes, such as person, vehicle, pistol, or rifle, and sometimes with bounding boxes showing exactly where the object appears in the image. The dataset is usually split into training, validation, and testing groups: training images teach the model, validation images help tune performance during development, and testing images measure how well the finished model performs on data it has not seen before.
Quantity Matters, But Quality Matters Just as Much
It is tempting to think that more data automatically means a better model. That is only partly true. A large dataset full of bad examples can actually make the model worse.
For example, someone building a firearms detection model might search public sources for pistol and rifle images. At first glance, this seems useful because there may be thousands of images available. But many public image datasets contain poor-quality or misleading examples, such as:
- Anime or cartoon guns
- Video game weapons
- Product marketing photos on white backgrounds
- Airsoft or toy guns
- Stock photography with staged poses
- Images where the weapon is huge, centered, and perfectly lit
- Photos unrelated to security-camera conditions
- Duplicates or near-duplicates
- Mislabeled images
This type of data may help a model learn what a firearm looks like in a clean, artificial setting, but it does not necessarily help the model detect a weapon in a real security environment. A pistol held at someone’s side in a dim hallway, partially blocked by clothing, captured at an awkward angle, and compressed by an IP camera is very different from a polished product photo of a handgun on a white background.
Real-World Security Detection Needs Real-World Images
A carefully crafted dataset is much more valuable. For security use cases, the best training data should look like the environment where the model will actually operate.
For firearms detection, higher-quality sources might include:
- Real-world security camera footage
- Body camera footage
- Training footage from law enforcement or military exercises
- De-identified incident footage where legally and ethically available
- Military or historical archives
- Controlled photo shoots using real cameras, realistic lighting, and realistic distances
- Action movie scenes, with limitations, when they resemble real camera perspectives and lighting
Even action movies can sometimes provide useful supplemental examples because they often include people holding firearms in more natural poses, varied lighting, movement, occlusion, and background clutter. However, they should not be treated as perfect real-world data. Movie scenes are staged, color-graded, professionally lit, and often captured with high-end cameras, so they may still differ significantly from actual surveillance footage.
The Negative Data Matters Too
Good datasets are not just about positive examples. For detection models, negative examples are equally important.
A firearms detection model should not only see pistols and rifles. It should also see objects that are commonly mistaken for firearms, such as:
- Cell phones
- Flashlights
- Tools
- Umbrellas
- Tripods
- Long shadows
- Black objects in hands
- Toys
- Hair dryers
- Camera equipment
- Tree branches
- Reflections
- Door handles
- People pointing fingers or holding unknown objects
Without strong negative examples, the model may become overly sensitive and generate false alarms. In a security operations center, too many false alarms can be almost as damaging as missed detections because operators eventually stop trusting the system.
Bad Data Creates Bad Models
A model trained mostly on clean internet images may perform well when tested against similar internet images. That does not mean it will perform well in a school hallway, parking lot, lobby, airport, warehouse, or exterior perimeter camera view.
This is one of the most common mistakes in vision model development: testing the model on data that looks too much like the training data. The model appears accurate because the test conditions are familiar. But once the model is deployed against real surveillance footage, performance drops because the real world is messier, darker, blurrier, more compressed, and less predictable.
What a Better Dataset Looks Like
A high-quality vision dataset should include:
- Realistic camera angles
- Different lighting conditions
- Day and night scenes
- Indoor and outdoor environments
- Motion blur
- Compression artifacts
- Partial obstruction
- Different distances from the camera
- Multiple body positions
- Different clothing types
- Different object sizes
- Diverse backgrounds
- Accurate labels
- Carefully reviewed false-positive examples
For a firearms model, the dataset should include both obvious and difficult examples. A rifle clearly visible in a person’s hands is useful, but so is a partially visible handgun near a waistband, a long gun seen from a distance, or a weapon visible for only a few frames.

The Bottom Line: Garbage In, Garbage Out
Vision model training follows the old rule of computing: garbage in, garbage out.
If the dataset is filled with cartoons, marketing photos, toy weapons, staged stock images, duplicates, and mislabeled examples, the model will learn from that bad data. It may become highly confident and still be wrong. For serious security applications, that is not acceptable.
High accuracy requires both good data and lots of it. A small, clean dataset may not be enough to generalize across real-world conditions. A huge, messy dataset may teach the model the wrong things. The best results come from large, carefully curated datasets that reflect the actual environment where the model will be used.
For vision detection and classification, the data is not just a starting point. It is the foundation. The better the source data, the better the model’s chance of making accurate, reliable decisions when it matters.